斯坦福AI团队“套壳”清华系开源大模型被实锤!被揭穿后全网删库跑路


整理|冬梅
5 月 29 日,一个来自斯坦福的作者团队在 Medium 上发布了一篇名为《Llama 3-V: Matching GPT4-V with a 100x smaller model and 500 dollars》的文章,文章中称他们训练出了一个比 GPT-4V、Gemini Ultra、Claude Opus 更强的 SOTA 开源多模态模型,尺寸比 GPT4-V 小 100 倍,训练成本仅需 500 美元。
斯坦福 AI 团队“套壳”清华系开源大模型被实锤该团队成员 Aksh Garg 也在 X(原 Twitter)上发贴介绍了这一模型的特点。没过多久该帖的浏览量已超过 30 万,被转发了 300 多次,Llama 3-V 的项目一下子冲到了 HuggingFace 首页。
随着该项目热度的持续走高,不少 X 和 HuggingFace 上的网友注意到,Llama 3-V 总是让人有种似曾相识的感觉,好像在哪里见到过!

网友们接着深扒后发现, Llama 3-V 似乎,有点,好像是套壳了清华系开源大模型 MiniCPM-Llama3-V 2.5。
据悉,MiniCPM-Llama3-V 2.5 是由清华系 AI 公司面壁智能推出并开源的 MiniCPM 系列最新的端侧多模态模型,总参数量为 8B,支持 30+ 种语言,多模态综合性能超越 GPT-4V-1106、Gemini Pro、Claude 3、Qwen-VL-Max 等商用闭源模型,OCR 能力及指令跟随能力得到进一步提升,可精准识别难图、长图、长文本。
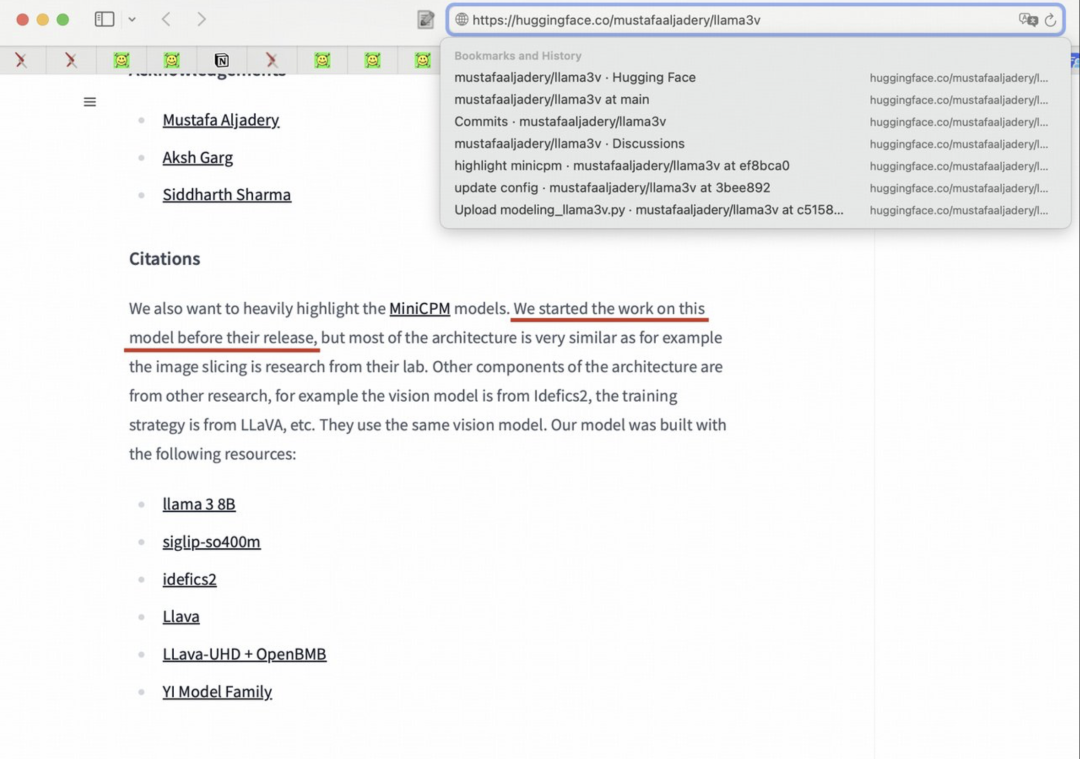
面对网友们的质疑,斯坦福这支 AI 团队也坐不住了,他们表示只是使用了 MiniCPM-Llama3-V 2.5 的 tokenizer,并且宣称在 MiniCPM-Llama3-V 2.5 发布前就开始了这项工作。
但他们的解释再次遭到了质疑。
通常情况下,一款模型及其详细的 tokenizer 往往是在其发布后才能被外人知晓,那么斯坦福这支 AI 团队如何能在 MiniCPM-Llama3-V 2.5 发布之前就获取到这些信息?
这件事持续在网上发酵。
6 月 2 日,不死心的网友在 Llama3-V 的 GitHub Issue 上发布质疑,或许是因为心虚,该条质疑的评论很快就被 Llama3-V 团队删除。
幸运的是,发布质疑的网友早已机智地提前截图保存了自己在 GitHub Issue 上发布的内容。

这名网友列举了在他看来 Llama3-V“套壳” MiniCPM-Llama3-V 2.5 的四点证据:
证据一:模型结构和代码几乎是双胞胎兄弟。
比如,套壳的 Llama3-V 与 MiniCPM-Llama3-V 2.5 几乎“共用”了完全相同的模型结构和代码。Llama3-V 的模型结构和配置文件与 MiniCPM-Llama3-V 2.5 完全相同,只是变量名不同。
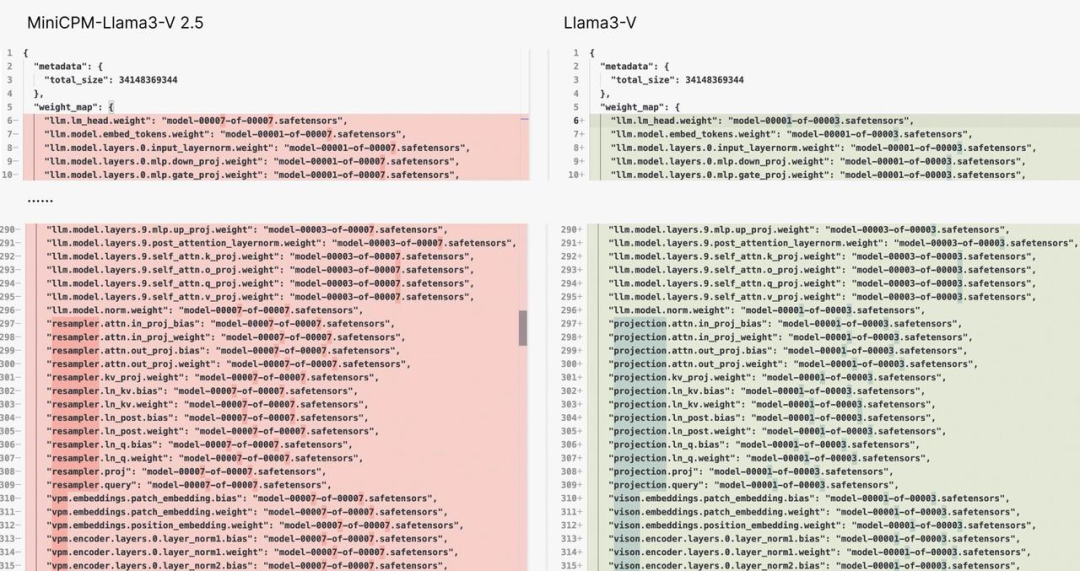
证据二:Llama3-V 的代码似乎就是 MiniCPM-Llama3-V 2.5 的代码。更令人震惊的是,Llama3-V 仅仅只是进行了一些重新格式化并把一些变量重新做了命名,比如图像切片、分词器、重采样器、数据加载等变量,下图是一些示例。

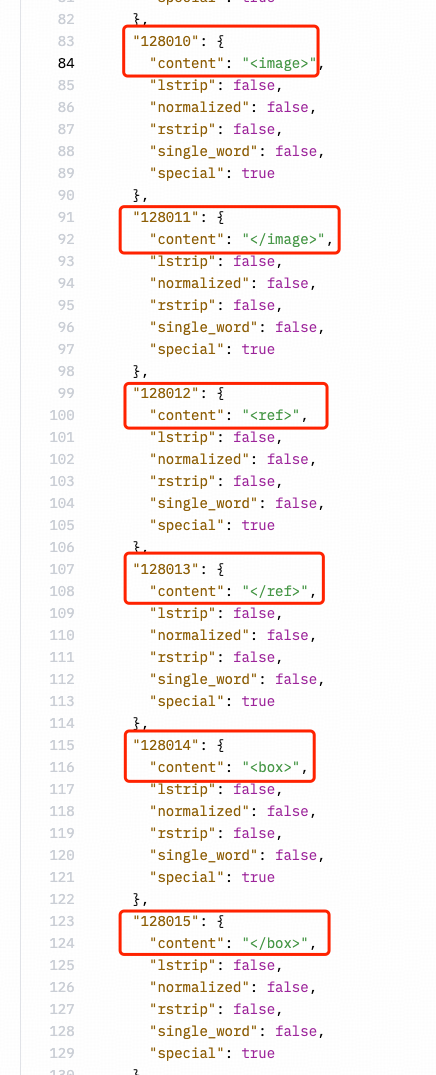
证据三:Llama3-V 的作者表示他们“引用了 LLaVA-UHD 作为架构”,还列出了差异点(关于 ViT 和 LLM 的选择)。但是他们并没有提到,这个项目的具体实现与 MiniCPM-Llama3-V 2.5 极其相似,却在空间模式等许多方面与 LLaVA-UHD 有非常多的差异。Llama3-V 也具有与 MiniCPM-Llama3V 2.5 相同的分词器,包括 MiniCPM-Llama3-V 2.5 新定义的特殊符号。
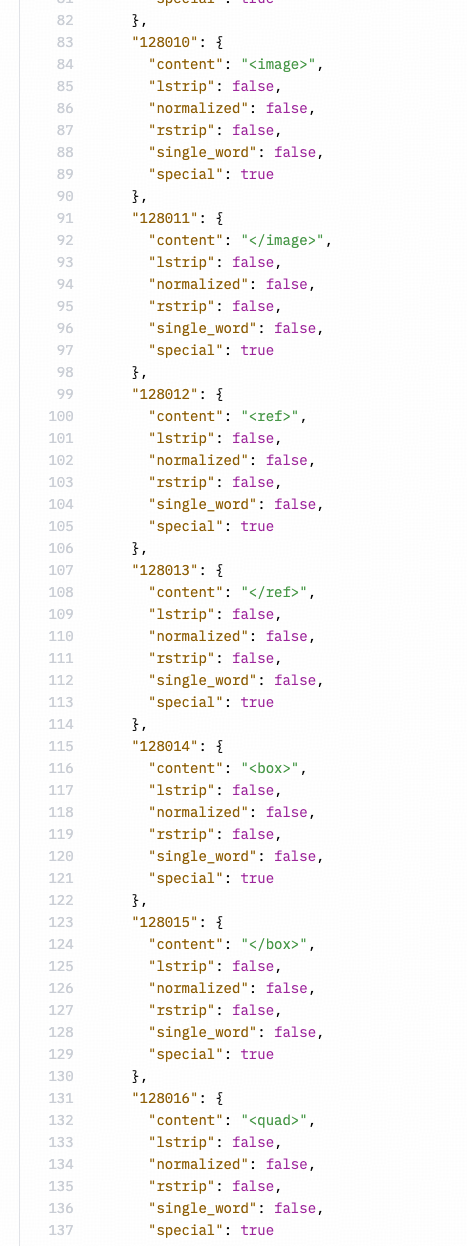
证据四:最初 Llama3-V 的作者在上传代码时直接导入了 MiniCPM-V 的代码,然后将名称更改为 Llama3-V。
https://huggingface.co/mustafaaljadery/llama3v/commit/3bee89259ecac051d5c3e58ab619e3fafef20ea6
在屡遭质疑后,斯坦福 AI 团队已经被逼到了不回应实在说不过去的地步了,有网友开脸贴大该项目的作者,“你们有没有勇气面对事实”?
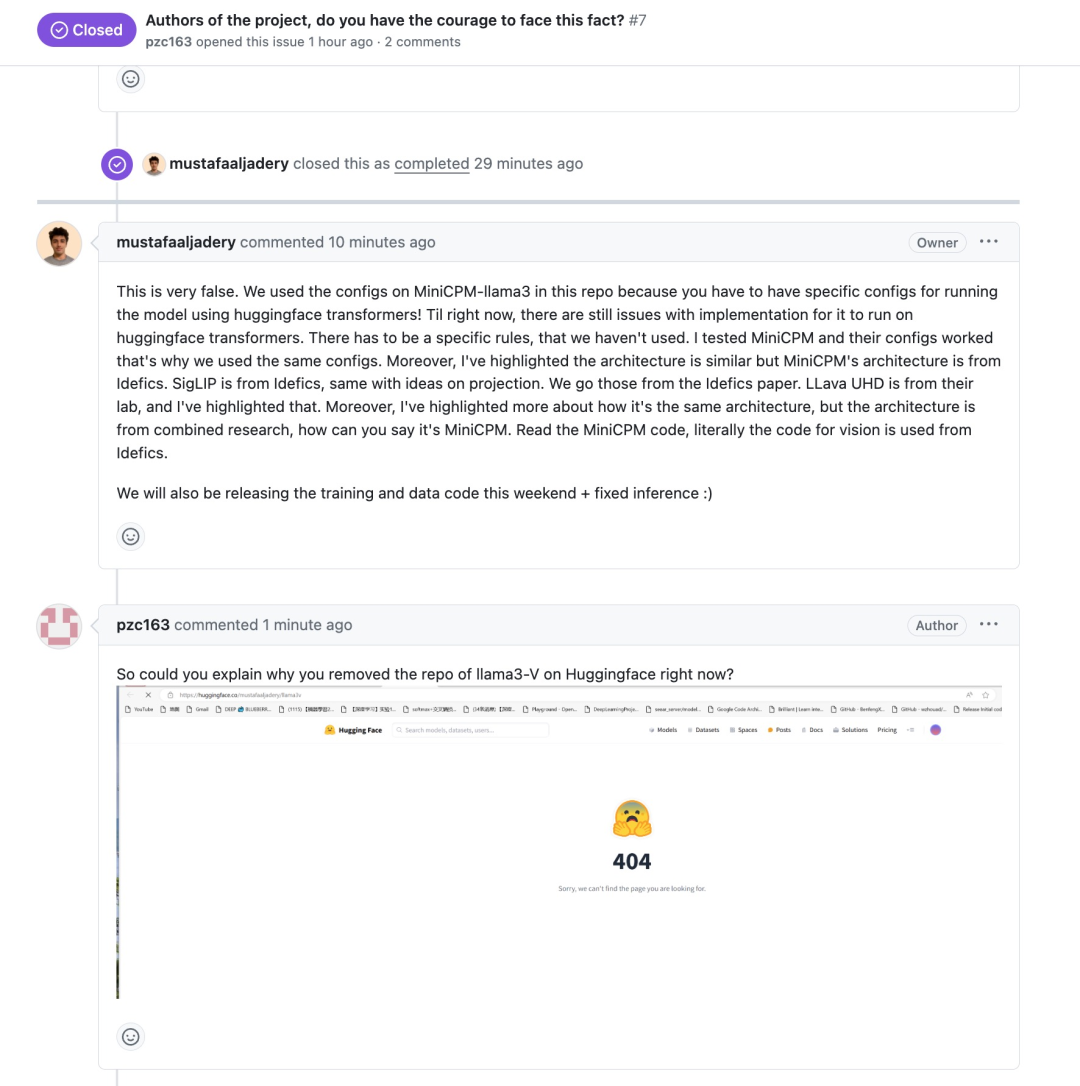
这种情况下,该团队成员不得不对网友关注的问题进行了回复。该项目中的一位作者表示:
“你们说我们抄袭简直是没影儿的事儿。Llama3-V 推理存在 bug,而 MiniCPM 的配置可以有效解决该问题,这就是为什么我们使用了相同的配置。此外,我已经指出了架构是相似的,但 MiniCPM 的架构来自 Idéfics。SigLIP 也来自 Idéfics。我们遵循 Idéfics 论文中的那些内容。LLava UHD 来自他们的实验室,我也已经指出了这一点。此外,我还强调了更多内容,即它是相同的架构,但该架构是基于综合研究的,你怎么能说它是 MiniCPM 呢?MiniCPM 的代码,看起来,视觉部分的也是从 Idéfics 那里使用的。”
不少网友还注意到,Llama3-V 在 MiniCPM-Llama3-V 2.5 项目发布之前就已经使用了 MiniCPM-Llama3-V 2.5 的 tokenizer 。有一些用户在 Twitter 和 HuggingFace 上指出以上问题后,Llama3-V 的作者表示他们只是使用了 MiniCPM-Llama3-V 2.5 的分词器(tokenizer)。他们还声称在 MiniCPM-Llama3-V 2.5 发布之前就开始了 Llama3-V 的工作。但令人无法解释的是,他们如何能在 MiniCPM-Llama3-V 2.5 发布之前就获取到其详细的分词器?
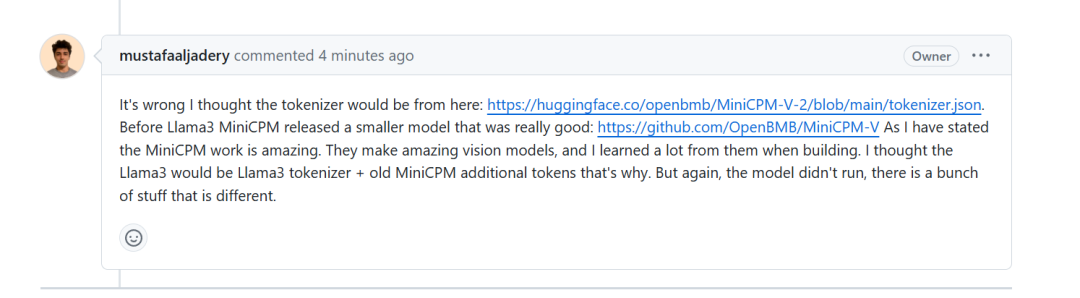
对此,Llama3-V 项目作者反驳说从已经发布的上一代 MinicPM-V-2 项目里拿的标记器。但实际上,有网友留意到,MiniCPM-V-2 的 tokenizer 与 MinicPM-Llama3-V2.5 完全不同,在 Huggingface 里是两个文件。既不是同一个 tokenizer 件,文件大小也完全不同。MinicPM-Llama3-v2.5 的 tokenizer 是 Llama3 的 tokenizer 加上 MiniCPM-V 系列模型的一些特殊 token 组成,MiniCPM-v2 因为在 Llama 3 开源之前就发布的,不会有 Llama 3 的分词器。
Llama3-V 团队屡遭质疑却始终咬死不认的态度,惹怒了面壁智能 MiniCPM-Llama3-V 2.5 团队的研究人员们。
6 月 3 日,面壁智能向 AI 前线列举了一些 Llama3-V 团队抄袭的“实锤”。
面壁智能认为,Llama3-V 项目的作者似乎并不完全理解 MiniCPM-Llama3-V 2.5 的架构,甚至也不理解他们自己的代码。
如下图 Llama3-V 的技术博客和代码显示, Llama3-V 的作者似乎没有完全理解 MiniCPM-Llama3-V 2.5 的架构,甚至也不懂他们"自己"(假若真是他们所写)的代码。
感知器重采样器(Perceiver resampler)是单层 cross-attention,而不是双层 self-attention。但是下图所示 Llama3-V 的技术博客里作者的理解很明显是错的。另外 SigLIP 的 Sigmoid 激活也不用于训练多模态大语言模型,而仅用于预训练 SigLIP。

截图来源:Llama3-V 的技术博客
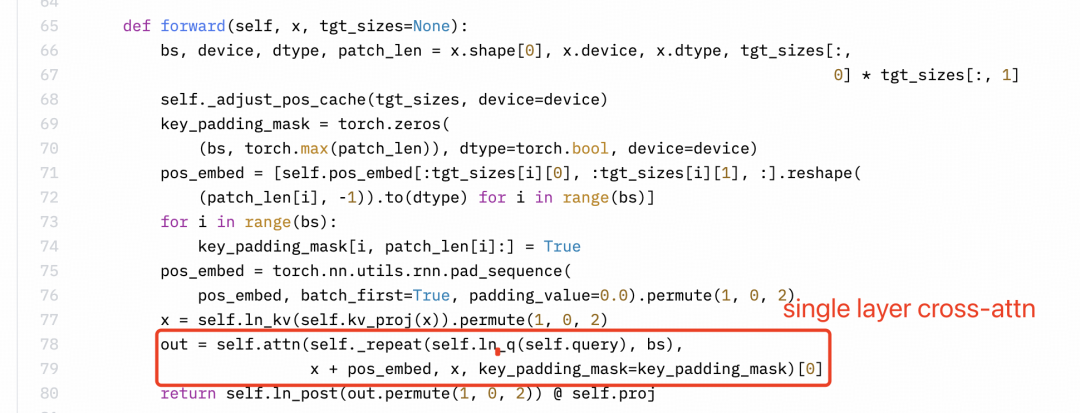
截图来源:Llama3-V 的代码
面壁智能团队还表示:“另外视觉特征提取不需要 Sigmoid 激活,但下图所示 Llama3-V 的技术博客里作者的理解是错的,但代码其实是正确的,这说明作者压根不理解自己的代码”。

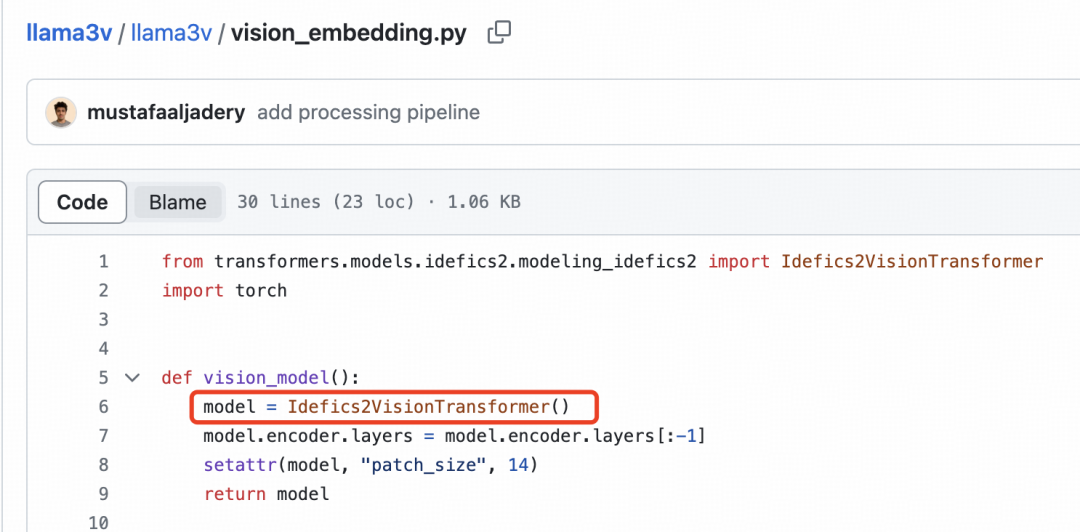
此外,Llama3-V 相当于 MiniCPM-Llama3-V 2.5 的加噪声版本。
据网友反馈,当运行 Llama3-V 时,作者提供的代码无法与 HuggingFace 上的 checkpoint 配合使用。
然而令人啼笑皆非的是,当把 Llama3-V 模型权重中的变量名更改为 MiniCPM-Llama3-V 2.5 的名称后,模型可以成功运行 MiniCPM-V 的代码。这一下子帮忙解决了困扰 Llama3-V 作者一周的问题。
如果在 MiniCPM-Llama3-V 2.5 的 checkpoint 上添加一个简单的高斯噪声(由一个标量参数化),你会预期得到什么结果?
new_dict = {}
for k, v in model.state_dict().items():
torch.cuda.manual_seed_all(42)
new_dict[k] = v + torch.randn_like(v) / 708
model.load_state_dict(new_dict)
结果是会得到一个行为与 Llama3-V 极为相似的模型。

然而,这些还不够。更更更炸裂的是,Llama3-V 团队连清华团队内部并未对外公开的私有数据都能拿到???

据面壁智能内部团队透露,Llama3-V 大模型居然能识别清华简,OCR 表现对比也很惊人,这些清华大学内部的私有数据他们又是如何拿到的呢?
MiniCPM-Llama3-V 2.5 的一个实验性功能是能够识别清华简,这是一种非常特殊且罕见的中国战国时期(公元前 475 年至公元前 221 年)写在竹简上的古文字。这些训练数据的采集和标注均有由清华 NLP 实验室和面壁智能团队完成,相关数据尚未对外公开。经过专有数据训练后,MiniCPM-Llama3-V 2.5 能够初步识别清华简的文字,甚至连犯的错误都一样。
然而令人惊讶的是,不可能获得专有数据训练的 Llama3-V 竟然也具有相同的能力!

下图展示了 Llama3-V 在识别清华简的文字时,其结果和 MiniCPM-Llama3-V 2.5 一致。

有趣的是,Llama3-V 在清华简识别犯错时竟然也和 MiniCPM-Llama3-V 2.5 一模一样。

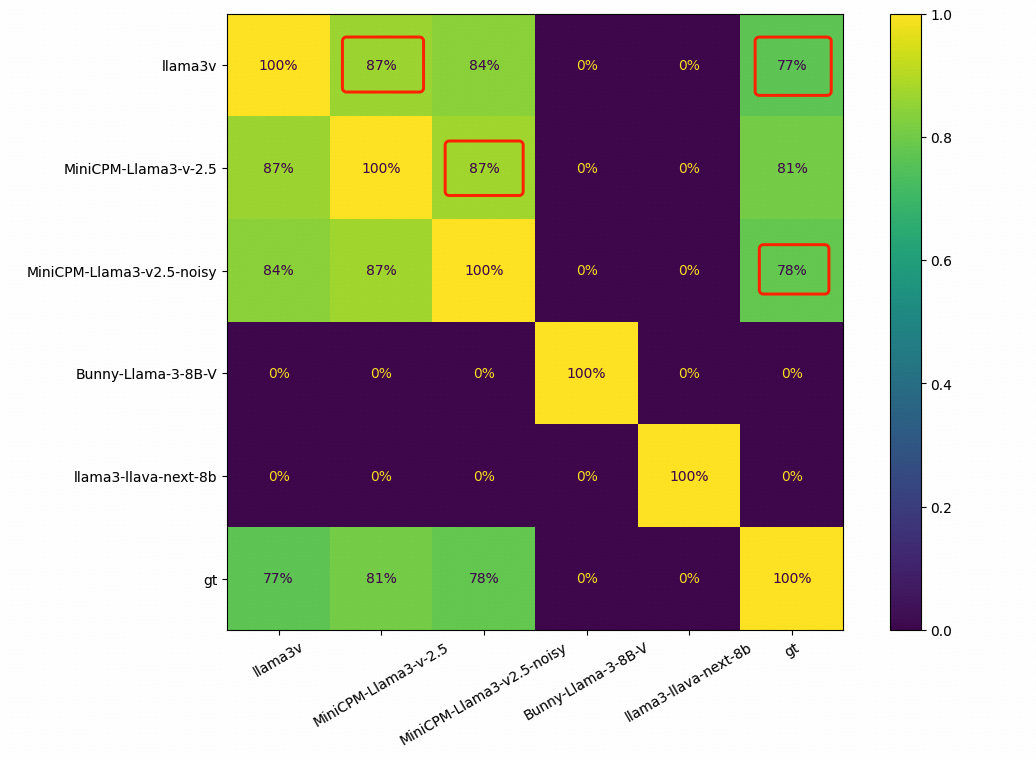
为谨慎起见,作者在 1000 张竹简图像上测试了几种基于 Llama3 的视觉 - 语言模型,并比较了每对模型的预测精确匹配。
结果显示,正常情况下每两个模型之间的重叠为零,而 Llama3-V 和 MiniCPM-Llama3-V 2.5 之间的重叠竟然达到了惊人的 87%!此外,MiniCPM-Llama3-V 2.5 和 Llama3-V 甚至在错误分布上也非常相似。Llama3-V 和 MiniCPM-Llama3-V 2.5 分别有 236 和 194 个错误预测,而其中重叠部分高达 182 个。
另外,这个高斯噪声对竹简字符也是有效的。
与 MiniCPM-Llama3-V 2.5 类似,Llama3-V 也显示出了很强的 OCR 能力,甚至包括中文。

Prompt:请输出图片中的文字
MiniCPM-Llama3-V 2.5
### 标题
9 倍像素更清晰
### 副标题
难图长图长文本精准识别
### 正文
OCR 技术进一步打磨,复杂推理与多模态识别能力再进化,MiniCPM-Llama3-V2.5 对于难图、长图、长文本的精准识别,再度带来出众表现!面壁自研高清图像高效编码技术,我们可以高效编码及无损识别 180 万高清像素图片,并且支持任意长宽比、甚至「有点变态」的 1:9 极限比例图像,突破了传统技术仅能识别 20 万像素小图的瓶颈。此前,MiniCPM-V 系列多模态模型就因对于街景、长图等困难场景的高效解析,赢得了良好口碑。
### 图片描述
1. **180 万像素 **
- 任意长宽比
- 图像无损识别
- 可支持
- 1:9 极限宽高比
Llama3-V
### 标题
9 倍像素更清晰
### 副标题
难图长图文本精准识别
### 正文
OCR 技术进一步打磨,复杂推理与多模态识别能力再进化,MiniCPM-Llama3-V2.5 对于难图、长文本的精准识别,再度带来出众表现。面壁自研高清图像高效编码技术,我们可以高效编码及无损识别 180 万高清像素图片,并且支持任意长宽比、甚至「有点变态」的 1:9 极限比例图像,突破了传统技术仅能识别 20 万像素小图的瓶颈。此前,MiniCPM-V 系列多模态模型就因对于街景、长图等困难场景的高效解析,赢得了良好口碑。
### 图片描述
- **180 万像素 **:任意长宽比,图像无损识别,可支持。
- **1:9 极限宽高比 **:可支持。
同样的事情也发生在内部的 WebAgent 数据上,这是一个已经整合但尚未发布的功能。
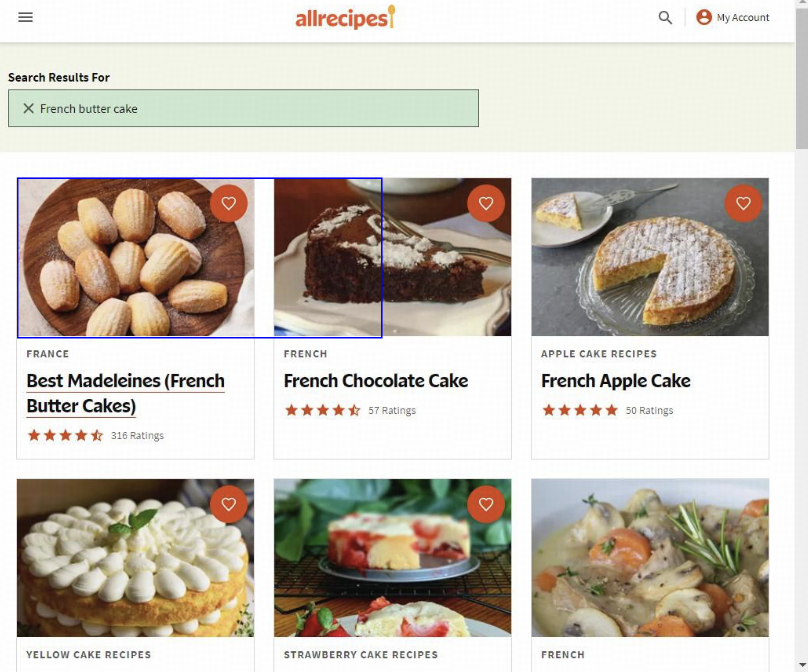
Q:
Actions History
click, input, click
Your Task
Can you give me a recipe for French butter cake?
Generate next actions to do this task.
minicpmv:
actions:
click,<box>32 273 477 508</box>
click,<box>32 273 477 508</box>
llama3v:
actions:
click,<box>32 273 477 508</box>
click,<box>32 273 477 508</box>

Q:
Your Task
有没有关于《黑子的篮球》的新剧场版的消息?
Generate next actions to do this task.
minicpmv:
actions:
hover,<box>732 292 792 328</box>
llama3v:
actions:
hover,<box>715 292 802 328</box>
事情发酵至此,就在网友们都等着斯坦福 AI 团队再次发文力证清白时,AI 前线留意到,该团队成员似乎集体“闭麦”,并且已经删除了他们在 X 上官宣模型的推文,连带着该项目在 Github 和 HuggingFace 上的库也已经删干净了。
Github 开源:
https://github.com/mustafaaljadery/llama3v(已删库)
HuggingFace 开源:
https://huggingface.co/mustafaaljadery/llama3v(已删库)
Medium 发布文章:
https://aksh-garg.medium.com/llama-3v-building-an-open-source-gpt-4v-competitor-in-under-500-7dd8f1f6c9ee
Twitter 官宣模型:
https://twitter.com/AkshGarg03/status/1795545445516931355(已删除)
而面壁智能团队成员也对此事进行了最新回应,他们表示看到这个消息还是挺让人伤心的。他们调查的结论是:
1、Llama3-V 可以使用更改参数名称后的 MiniCPM-Llama3-V 2.5 的代码和配置来运行
2、它的行为类似于 MiniCPM-Llama3-V 2.5 在内部数据上训练的未透露的实验特征,例如识别清华简(一种特殊类型的古代汉字)和 GUIAgent
3、它有点类似于噪声版的 MiniCPM-Llama3-V 2.5?

*博客内容为网友个人发布,仅代表博主个人观点,如有侵权请联系工作人员删除。



