
AXI协议的深入分析
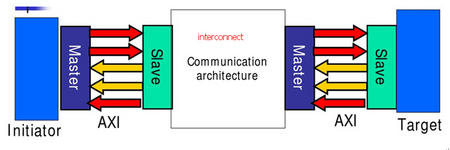
1、AXI总线将写地址通道、写数据通道、写响应通道、读地址通道、读数据通道分开,这是AXI总线效率比较高的一个原因,类似于全双工的感觉,每个通道互不干扰却又彼此依赖;但是为什么写会出现三个通道,但是读却只有两个通道呢,那是因为读将读数据通道和读响应通道合并成了读数据通道,因为读数据和读响应都由slave发出,当最后一笔数据被读出的时候,slave完全可以在这个时候给出当前这个burst读状态(例如是ok还是error),但是写就不同了,虽然写数据可能已经被slave接收了,但是接收完最后一笔数据的时候,slave可能不能及时反馈当前这个burst是否写成功,因为数据可能并没有完全到达目的地;而且写成功与否肯定是slave应答,所以单独开辟了写响应通道。
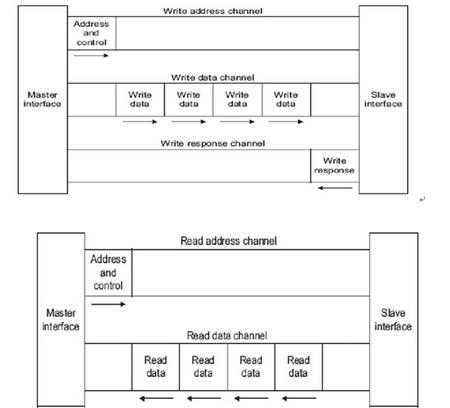
2、AXI传输首先发出burst的长度(burst-len),最大是16,burst长度就代表有多少个transfer或者beat,一个transfer就代表一个数据位宽的数据,所以一个burst最大的传输数据长度为burst_len*transfer_width;在发出burst长度时会同时发出当前这个burst中第一个transfer的首地址,后面其它的transfer不会有地址,slave要根据地址递增的方式自己去进行相应的处理,这个地址可以是非对齐的;在发出burst长度时会同时发出burst_size,这个size代表当前burst中所有transfer中最大的字节个数,在发出burst长度时会同时发出地址递增方式burst-type,是不变地址(non-incr),是递增(incr)还是wrap,例如:当前要传输11个字节,地址是2,数据位宽是4B,所以传输方式是:2B-4B-4B-1B,burst_len=4,burst_size=4(所有transfer中size最大的),地址是2(因为支持非对齐传输),burst-type=incr;对于写会有strobe代表当前transfer中哪几个字节是有效的,所以上面的strobe为:1100-1111-1111-0001,对于读则没有,但是Master自己清楚哪些数据是有效的,所以可以将整个4B都读出来,master自己去除无用的数据。

注意:不同人对burst_size(也就是英文手册中AWsize和ARsize的理解)的理解可能不同,手册中在table-4-2中有解释,它表示一个burst中transfer中max-num,注意最大,所以不是表示当前burst中所有transfer的num,只是表示最大。如果表示所有transfer的num,那么也就是所有transfer的大小是一样的(AHB就是这样的,每个burst中的transfersize是一样的),那么上面的例子就必须分成3个burst,第一个burst,len=1,size=2,addr=2, 第二个burst,len=2,size=4,addr=4, 第三个burst,len=1,size=1,addr=12,显然这个效率要比上面的低。不过呢,如果你的设计中大家都约定成统一的理解倒也可以实现,只是你的AXI就不是通用的AXI,别人不能用。
3、AXI中关于valid和ready的关系在3.3节中有很好的解释,在设计时一定不能设计一方依赖另一方,否则会出现死锁的现象,valid可以优先于ready拉高,也可以在ready之后拉高,它们并无先后关系,其实只要是master准备好就可以valid,slave准备好就可以ready,并无绝对的先后顺序,但是当两者同时为高则表示当前的data或者cmd结束或者开始下一个data或者cmd。
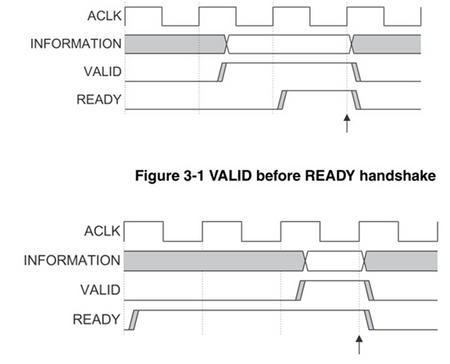
4、由于3中的不确定性会出现一种奇葩的现象,以写为例,会出现写数据比写地址先到达slave的现象,原因如下:假如AWREADY和WREADY被slave提前拉高了,虽然master那边肯定是先发地址再发数据,但是master会误以为slave能够立即接收地址,所以地址发送完立即发送数据,但是地址通道和数据通道是分开的,axi允许单独对各个通道进行优化,所以,如果地址通道被插入了多个reg,那么就会造成延时,可能出现数据先被slave收到。

为了避免上面的现象该怎么办呢,首先slave最好不要在接收到地址之前就将WREADY拉高(但是AWREADY建议提前拉高,这样address握手可能就会在一个周期内完成,否则至少需要两个周期,就像上图),要在收到地址后才进行WREADY的处理,或者slave先buffer住收到的数据,然后等到收到地址后再做处理。不过我觉得AXI interconnect应该会处理这种情况,不会让数据先于地址到达slave的,所以ARM公司的AXI产品肯定是不会有问题的,但是如果不购买相应的AXI interconnect而自己开发时就要注意上面的问题。
5、AXI最多支持16个master,16个slave,它们可以通过AXI interconnect连接,不同的master发出的id可能相同,但是经过AXI interconnect处理后会变得唯一,所以自己开发AXI interconnect也要注意这个问题。同一个master发出的id可以相同也可以不同,相同的id数据传输必须按照先后顺序否则会出现错误,不能乱序和交叉。AXI 支持ID方式,这也是该总线效率较高的一个原因。
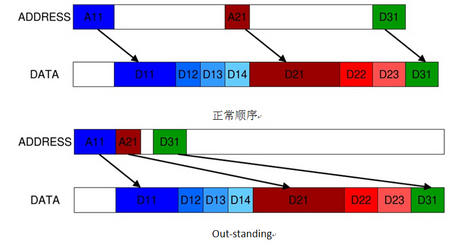
6、AXI支持out-standing或者multi-issue(即当前传输没结束就发起下一个传输)乱序和交叉传输,依靠ID进行区分。这也是AXI总线协议效率较高的一个原因。
7、这块的理解是参考别的网站的,并不确定正确性,cachalbe和 bufferable的概念比较复杂,具体可以看看ARM cache相关文档。简单说,这两个概念都是围绕master访问的slave的请求来说的。例如该请求时cacheable的写话,那么实际的写数据不一定更新了主存内容,可以只更新了cache,以后再通过write back方式更新;bufferable也类似,如果是写,那么写数据响应返回给master时,实际写数据不一定到达了slave设备。这个写数据可能被buffer了,而时间未知。如果不是bufferable则写响应反映了slave实际接收到数据的时刻。说的比较笼统,具体可以参考相应文档。
8、低功耗的理解(参考):AXI的低功耗接口本身也是数据传输协议的扩展。它针对自身具有低功耗处理的设备和自身不具有低功耗处理的设备都是通用的。
AXI低功耗控制接口包括两类信号:
设备给出表示当前时钟是否可以被gated的信号。外设使用CACTIVE信号表明它希望时钟,时钟控制模块必须马上给设置时钟。
对于系统时钟控制模块,提供可以进入或退出低功耗状态的握手信号。CSYSREQ表明了系统请求设备进入低功耗状态,而设备使用CSYSACK信号来握手低功耗状态请求和退出。
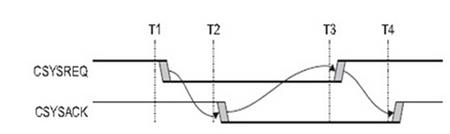
图2 AXI低功耗握手时序(1)
在CSYSREQ和CSYSACK信号为高的时候,也就是T1时刻之前,设备处于正常状态。在T1时刻,系统拉低了CSYSREQ信号,在T2时刻,外设 拉低CSYSACK信号。在T3时刻系统拉高CSYSREQ表示系统要求设备从低功耗状态退出。T4时刻设备握手拉高CSYSACK表明已经退出。在握手 中,CACTIVE可以作为拒绝或者同意的标志。下图中CATIVE一直拉高,来表示当前不接受这种低功耗的请求,而不是依靠ACK信号。可以看 出,ACK 信号只是表示状态迁移的完整性,而对于是否进入低功耗状态,需要CACTIVE信号表示。同时该信号也表示了设备在低功耗状态需要退出。
在系统层面的操作:
有两种方法进行设备的低功耗控制。第一种是系统不断的轮询设备,一旦某个设备可以进入低功耗状态,就把相应的CATIVE 拉低,然后把CSYSACK信号拉低。这样做的效率不是很高,系统并不知道哪个设备已经可以提前进入低功耗状态,而是简单的按照时间进行查询,并不能精确 的控制。这一种方案主要强调系统与设备的强耦合性。只有系统需要的时候才开始轮询,系统不需要,就不能进入低功耗模式。
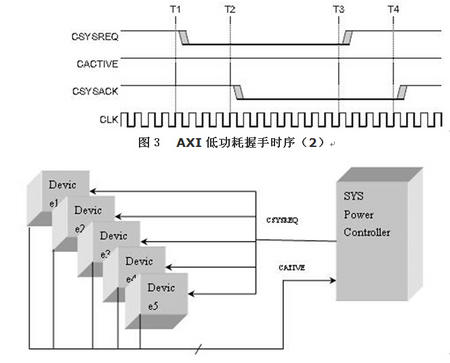
第二种方法是系统被动接受设备发出来的CATIVE,然后开始低功耗处理流程。这样可以提高效率。但是可能系统由于预测到马上需要使用该device,不发起低功耗请求。值得注意的是,两种低功耗管理是可以混合使用的。
(转自sunyzz ) STM32
STM32 MCU
MCU 通讯及无线技术
通讯及无线技术 物联网技术
物联网技术 电子DIY
电子DIY 板卡试用
板卡试用 基础知识
基础知识 软件与操作系统
软件与操作系统 我爱生活
我爱生活 小e食堂
小e食堂