摩尔线程CEO张建中:万卡集群是AI主战场上的标配

「从今天起,世界彻底改变了。」这是 GPT-3 算法的发明人埃德·莱昂·克林格在 GPT-3 出现时说的一句话。
本文引用地址://www.cazqn.com/article/202407/460864.htm这是一个 AI 的时代,这是一个算力的时代。
今日,摩尔线程重磅宣布其 AI 旗舰产品夸娥(KUAE)智算集群解决方案实现重大升级,从当前的千卡级别大幅扩展至万卡规模。
同时,摩尔线程联合中国移动通信集团青海有限公司、中国联通青海公司、北京德道信科集团、中国能源建设股份有限公司总承包公司、桂林华崛大数据科技有限公司,分别就三个万卡集群项目进行了战略签约,多方聚力共同构建好用的国产 GPU 集群。
此外,我们从现场也看到摩尔线程的产品能力和强大的生态链接力。与来自清华系两家公司无问芯穹和清程极智已经开始深度合作,无问芯穹是由清华大学电子工程系系主任汪玉教授发起的,清程极智由清华大学计算机系郑纬民院士发起的。还有京东、360、智平方等多家国内企业,夸娥智算集群助力其在大模型训练、大模型推理、具身智能等不同场景和领域的创新。
万卡是最低标配
大模型自问世以来,关于其未来的走向和发展趋势亟待时间验证,但从当前来看,几种演进趋势值得关注,使得其对算力的核心需求也愈发明晰。
第一,Scaling Law 将持续奏效。需要单点规模够大并且通用的算力才能快速跟上技术演进。第二,Transformer 架构不能实现大一统,和其他架构会持续演进并共存,形成多元化的技术生态。第三,AI、3D 和 HPC 跨技术与跨领域融合不断加速,大模型的训练和应用环境更加复杂多元。
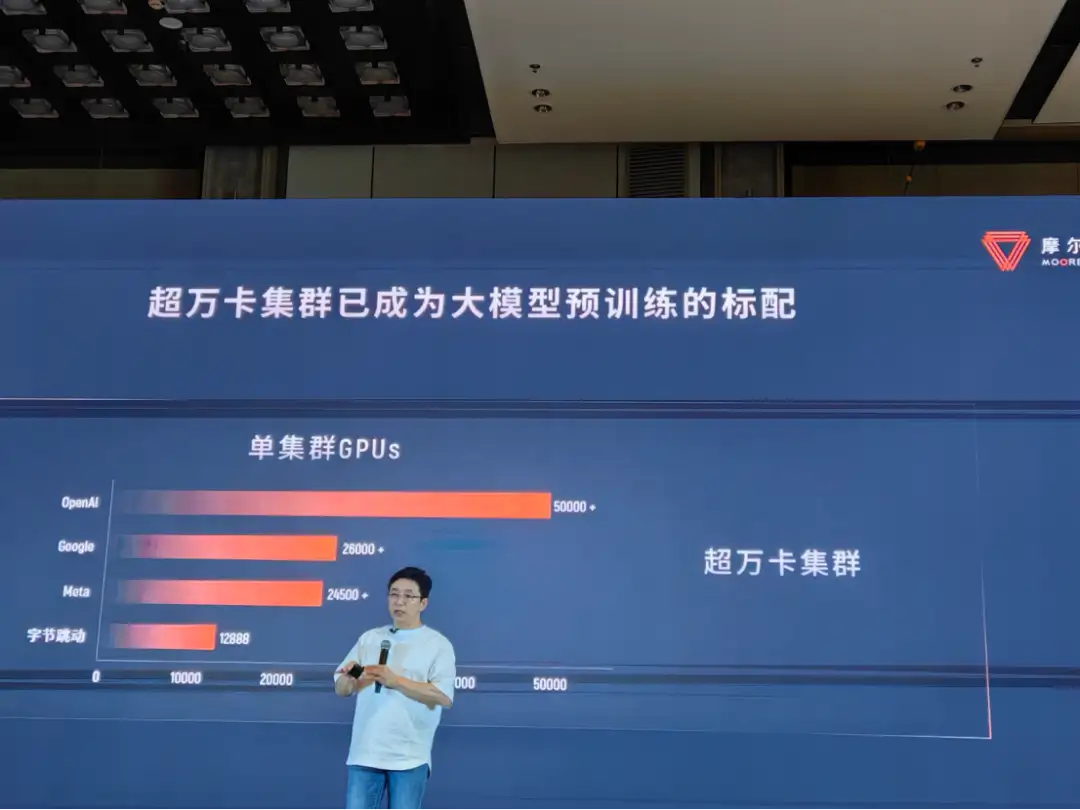
随着计算量不断攀升,大模型训练亟需超级工厂,即一个「大且通用」的加速计算平台,以缩短训练时间。以 Llama 3 为例,在它问世之际,Meta 就公布了其基础设施详情:「我们在两个定制的 24K GPU 集群上做训练。」
摩尔线程创始人张建中提出了一个标准:「AI 主战场,万卡是最低标配。」
国产万卡万 P 万亿大模型训练平台
夸娥(KUAE)是摩尔线程智算中心全栈解决方案,是以全功能 GPU 为底座,软硬一体化、完整的系统级算力解决方案,包括以夸娥计算集群为核心的基础设施、夸娥集群管理平台(KUAE Platform)以及夸娥大模型服务平台(KUAE ModelStudio),旨在以一体化交付的方式解决大规模 GPU 算力的建设和运营管理问题。

基于对 AI 算力需求的深刻洞察和前瞻性布局,摩尔线程夸娥智算集群可实现从千卡至万卡集群的无缝扩展,旨在满足大模型时代对于算力「规模够大+计算通用+生态兼容」的核心需求,通过整合超大规模的 GPU 万卡集群、极致的计算效率优化以及高度稳定的运行环境,以万卡智算集群的新超级工程,重新定义国产集群计算能力的新标准。
夸娥万卡智算解决方案具备多个核心特性:
超大算力,万卡万 P。浮点运算能力达到 10Exa-Flops,大幅提升单集群计算性能,能够为万亿参数级别大模型训练提供坚实算力基础。
超高稳定,月级长稳训练。在集群稳定性方面,摩尔线程夸娥万卡集群平均无故障运行时间超过 15 天,最长可实现大模型稳定训练 30 天以上,周均训练有效率在 99% 以上,远超行业平均水平。
极致优化,超高 MFU:实现大模型的高效率训练,MFU 最高可达到 60%。在系统软件层面,基于极致的计算和通讯效率优化等技术手段,大幅提升集群的执行效率和性能表现。
全能通用,生态友好:可加速 LLM、MoE、多模态、Mamba 等不同架构、不同模态的大模型。s 同时,基于高效易用的 MUSA 编程语言、完整兼容 CUDA 能力和自动化迁移工具 Musify,加速新模型「Day0」级迁移,实现生态适配「Instant On」,助力客户业务快速上线。
构建万卡集群并非一万张 GPU 卡的简单堆叠,而是一项高度复杂的超级系统工程。它涉及到超大规模的组网互联、高效率的集群计算、长期稳定性和高可用性等诸多技术难题。
张建中也感叹到:「万卡集成的难度比登喜马拉雅山还难。」
共建大模型应用生态
根据《2023~2024 年中国人工智能计算力发展评估报告》,中国智能算力规模正处于高速增长状态。预计到 2027 年,中国智能算力规模将达 1117.4EFLOPS,2022~2027 年期间的年复合增长率为 33.9%。
万卡集群的建设需要产业界的齐心协力,为实现大模型创新应用的快速落地,让国产算力「为用而建」。
在今日的发布会线程,摩尔线程携手中国移动通信集团青海有限公司、中国联通青海公司、北京德道信科集团、中国能源建设股份有限公司总承包公司、桂林华崛大数据科技有限公司,分别就青海零碳产业园万卡集群项目、青海高原夸娥万卡集群项目、广西东盟万卡集群项目进行了战略签约。

今年 5 月,摩尔线程与无问芯穹正式完成基于国产全功能 GPU 千卡集群的 3B 规模大模型实训。该模型名为「MT-infini-3B」。MT-infini-3B 模型训练总用时 13.2 天,经过精度调试,实现全程稳定训练不中断,集群训练稳定性达到 100%,千卡训练和单机相比扩展效率超过 90%。在行业内率先开启了国产大语言模型与国产 GPU 千卡智算集群深度合作的新范式。
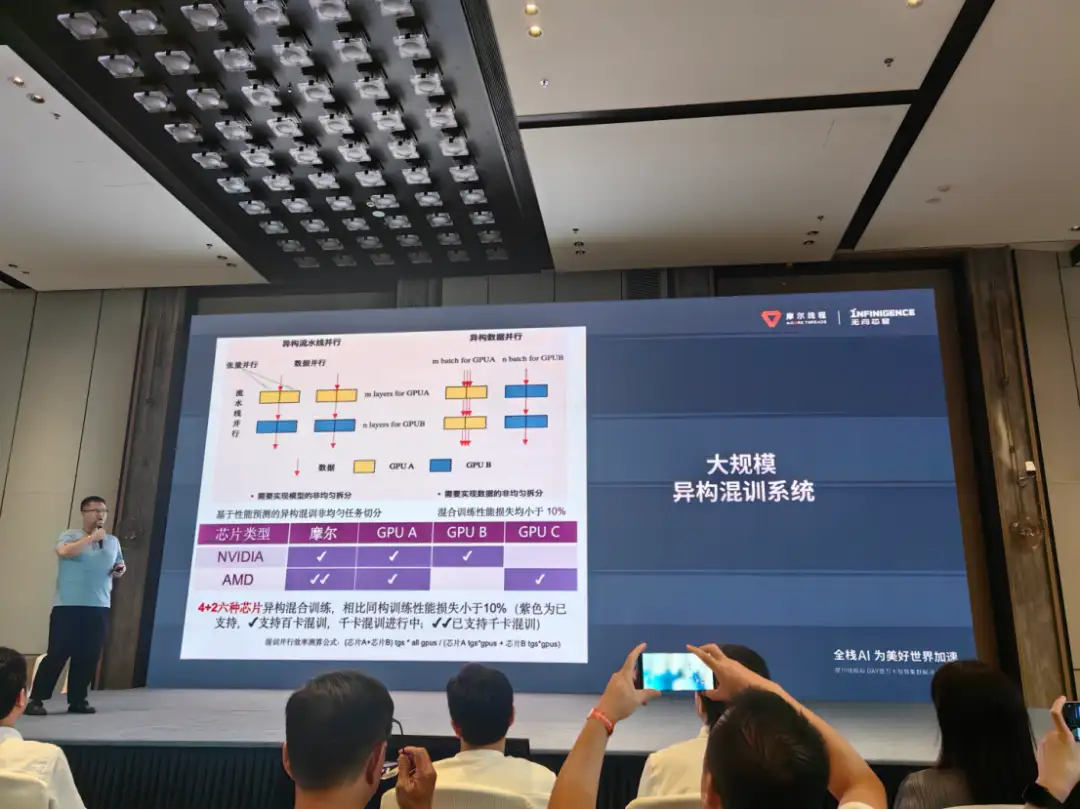
清程极智与摩尔线程合作的过程中,发现其硬件架构、指令集、编译器、MUSA 软件栈等设计非常优秀,极具潜力。清程极智将与摩尔线程强强联合,携手打造世界水平的大模型基础设施。

此外,摩尔线程还与360、京东云、智平方等多家国内企业合作。
结语
随着今年「AI+」首次被写入两会工作报告,AI 算力成为新质生产力的重要引擎。
智算中心不应只是硬件的堆积,更是对软硬一体化的 GPU 智算系统整合能力的考验,GPU 分布式计算系统的适配、算力集群的管理和高效推理引擎的应用等,都是提高算力中心可用性的重要因素。
四年多的潜心发展,摩尔线程在 AI GPU 方面具备了强劲的实力,构建起了一张包括芯片、板卡、服务器、集群和软件栈的全栈 AI 产品版图,并且已经多点实现落地。
正如摩尔线程创始人兼 CEO 张建中所言:「当前,我们正处在生成式人工智能的黄金时代,技术交织催动智能涌现,GPU 成为加速新技术浪潮来临的创新引擎。夸娥万卡智算集群作为摩尔线程全栈 AI 战略的一块重要拼图,可为各行各业数智化转型提供澎湃算力,不仅有力彰显了摩尔线程在技术创新和工程实践上的实力,更将成为推动 AI 产业发展的新起点。」




评论