婴儿啼哭监测及安抚系统*

*本文受陕西省重点研发计划项目(2020ZDXM5-01)和中央高校业务费项目(XJS220209)支持
本文引用地址://www.cazqn.com/article/202303/444887.htm照顾婴儿是一项辛苦的工作,婴儿往往会因为环境的轻微的变化而产生啼哭行为,需要父母去安抚,这耗费了父母的大量精力,影响了父母正常的工作和生活。随着语音识别技术的迅速发展,语音识别已经成为各类边缘嵌入式电子系统的重要感知手段。针对婴儿领域的产品也是层出不穷,其中包括针对婴儿啼哭声识别的产品。
随着人机交互、语音识别、嵌入式等技术在智能家居领域的快速应用,出现了一系列高度智能化、便捷化的商业产品,诸如扫地机器人、小米音箱、智能门锁和智能监控摄像头等。同时智能化的婴儿看护产品也逐渐兴起并推广开来,为母婴用户带来了巨大的便利,用户不用时刻陪伴在婴儿身边。本文就婴儿啼哭识别系统进行设计,力图以简易的方式和方法搭建一个婴儿啼哭声识别系统。
1 系统设计
1.1 系统组成部分
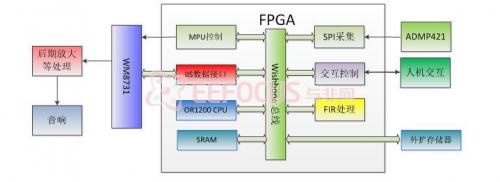
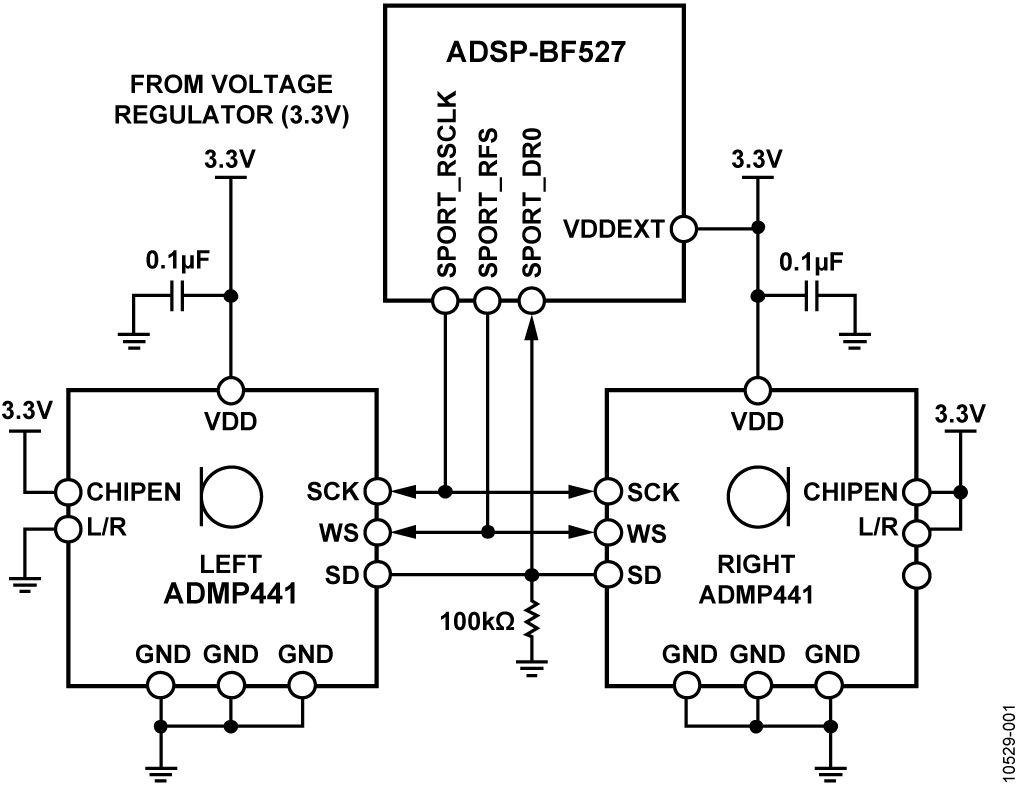
如图1 所示,该系统主要分为4 个组成部分,首先是声音拾取与信号调理模块,模块使用集成硅麦克风芯片拾取环境声音,经自动增益电路调理后接入处理器AD采集端口。然后是处理器主控模块,MCU以pingpong工作机制同时完成采集操作与信号处理操作,其中信号处理程序包括预处理、端点检测、基音频率提取3个部分。最后是语音安抚模块与无线通信模块,当识别到有效婴儿啼哭声时,语音安抚模块将播放音乐,无线通信模块将通知监护人。

1.2 系统工作过程
婴儿啼哭监测及安抚系统的工作过程如下:首先,由声音拾取与信号调理模块的声音拾取芯片(MEMS 硅麦克风)收集环境声音,经信号调理电路完成自动增益后由处理器主控模块采集,处理器主控模块采集到音频数据后,将首先通过获取环境信号特征完成环境噪声与端点检测特征值自适应,然后对音频信号预处理,最后通过端点检测算法提取出有音信号段,如处理器主控模块检测到有效的音频信号段,则通过MFCC 算法提取此段信号的频率特征,然后根据音频信号频率倒谱提取出基音频率,最后通过基音频率各类统计值做最后判断,若识别结果为有效婴儿啼哭声,则触发安抚行为,包括驱动语音安抚模块播放安抚音乐与父母安抚声,驱动无线通信模块通知父母婴儿发生啼哭。
2 系统功能实现与工作原理
2.1 硬件部分
2.1.1 采集与信号调理模块
麦克风采用MEMS微型硅麦克风,MEMS 麦克风将电容器集成在微硅晶片上,可以采用表贴工艺进行制造,直径不到1 mm 的小型薄膜的重量非常轻巧,且与ECM相比,MEMS麦克风会对由安装在同一PCB上的扬声器引起的PCB噪声产生更低的振动耦合;另外,它也具有改进的噪声消除性能与良好的RF 及EMI 抑制。
2.1.2 语音安抚及无线通信模块
语音安抚模块采用YX5200-24SS作为主芯片,YX5200-24SS是一个支持串口的语音芯片,集成了MP3、WAV、WMA的硬解码;预先将安抚音乐与父母的安抚音频存入,安抚事件触发信号到来时,将通过串口驱动语音安抚模块播放某一安抚音频。而无线通信模块采样集成蓝牙芯片,安抚事件触发信号到来时将通知父母监测到婴儿啼哭。
2.2 软件部分
2.2.1 预处理
预处理程序流程图如图2所示,所述的信号预处理程序的流程为:当预处理程序接收到采集的信号后,首先求取此段信号均值,然后利用均值完成噪声自适应与端点检测特征值自适应,完成自适应之后,对原信号完成预加重操作,增强高频成分,最后将此段信号按设定的帧长与帧移完成分帧操作即可传入端点检测程序。
预加重的目的是提升高频部分,使信号的频谱变得平坦,使得全频带尽可能的均衡,以此来补偿语音信号受到发音系统所抑制的高频部分,突出高频的共振峰;然后是信号分帧处理,由于傅里叶变换要求输入信号是平稳的,非平稳信号的傅里叶变换是没有意义的,而短时傅里叶变换可对其完成分析;语音信号就是非平稳信号,但其在短时上是有一定的周期性的,即在1 个较短的时间片里它可被认定为接近平稳信号,因此要进行分帧的操作,即截取短时的语音片段;而语音的基频在(100~250)Hz,即基音周期在(4~10)ms,而每帧含有2~3 个周期主频能量表现才较佳,这里采用8 kHz采样率,帧长256,即32 ms;此外,分帧时的帧移取128,即相邻两帧将有部分重叠,可使此段信号计算得到的基音频率更加平滑,也可减弱后续加窗操作的副作用。

2.2.2 端点检测
端点检测程序流程图如图3 所示,所述的端点检测程序流程为:完成预处理的音频信号传入后,首先根据噪声自适应值设定短时幅度累计阈值,然后设定短时过零阈值,其中短时幅度累计值通过预处理过程得到的幅度累积阈值乘系数得到,而短时过零率的“0 点”则为预处理过程得到的噪声阈值计算出的以0 点为中心的1个窗口,窗口内的值都被认为是0 值,输入信号相邻两个值分别大于窗口与小于窗口,则视为一次过0。然后遍历所有帧,根据两个阈值获得有音声段,然后将有音声段帧序号传入基音频率提取程序。

2.2.3 基音频率提取
基音频率提取程序流程图如图4 所示,所述的基音频率求取程序的流程为:有音声段传入后,此程序将依次处理每个有音声段帧,首先对帧数据进行窗函数滤波操作,然后输入FFT 算法输入端,再对FFT 算法输出的复数数组求取幅值,再对幅值取对数,最后再带入IFFT算法求得倒谱,然后求得基音频率及其统计特征,如果基音频率超过设定的频率阈值,则判定为识别到有效婴儿啼哭,最后将会触发安抚模块。

3 项目测试
婴儿啼哭监测及安抚系统于3 个场景下完成了12 h长时间测试,分别是睡觉环境、人声环境、客厅环境,分别代表仅含环境白噪声、除环境白噪声外还包含说话声与家具移动声、除环境白噪声还包含电视机声音与音乐声音;经测试,在睡觉环境中,识别准确率高于99.9%;在人声环境中,识别准确率大约为97.73%;在客厅环境中,识别准确率大约为94.97%。此外婴儿啼哭监测及安抚系统还有一参数可按情况调整,此参数为单位时间内有效输出验证次数,即在1 s 时间内,识别到几次婴儿啼哭声则视为有效婴儿啼哭,此参数越大则误判率越低,对应的实时性越差,以上测试此参数皆设为2,输出延迟约0.3 s,通过设置此参数可在实时性和准确性之间寻求一个平衡。

图5 玩偶嵌入智能识别系统
4 结束语
本系统采用基于音频特征的语音识别方案,通过提取婴儿啼哭声的倒谱特征,进而得到婴儿啼哭声的基音频率及其统计特征来判定婴儿啼哭声的存在,降低了对处理器存储器容量以及对处理器算力的要求,降低了成本,此外系统采用ping-pong 工作机制,实时性强,经测试平均延迟为200 ms,本系统可广泛应用于智能玩偶及智能童车等。
参考文献:
[1] 梁海珍.语音识别技术在智能家居领域应用[J].电子技术与软件工程, 2021,2(4):100- 101.
[2] 赵春昊,莫重骥,矫欣航,等.声纹识别技术发展与应用浅谈[J].中国安全防范技术与应用, 2020,10(5):17-20.
[3] 鱼昆,张绍阳,侯佳正,等.语音识别及端到端技术现状及展望[J].计算机系统应用,2021,3 (3):14-23.
(本文来源于威廉希尔 官网app 杂志2023年3月期)





评论